Self-Hosting Harbor on K8s
Integrating Harbor as a self-hosted container registry for a K8s cluster — why over a cloud CR, dev architecture, and a fault-tolerant production design

Background
A Container Registry (CR) is a secure storage and distribution system for container images. If you’ve used AWS, you’ve most likely encountered ECR (Elastic Container Registry). Cloud-provider CRs are great for reliability and security, but the cost ramps up quickly — per-GB-month storage adds up over time, and cross-region or internet pulls bill at egress rates on top of that.
For environments where that reliability ceiling isn’t strictly needed — development, staging, internal builds — many teams reach for an open-source registry running on-prem. Harbor is the typical pick because it wraps the basic OCI registry with the things you actually want in practice:
- CNCF-graduated — same maturity bar as Kubernetes itself; production deployments are well-documented.
- Multi-tenancy + RBAC — projects, robot accounts, and per-project quotas, instead of “one bucket of images everyone shares.”
- Built-in vulnerability scanning via Trivy (CVE scan of OS packages and language deps in each layer).
- Image signing + replication — Cosign integration and pull/push replication policies between registries. (Proxy Cache projects also support on-demand mirroring of Docker Hub.)
The
developmentOn-Premise environment here is using K8s (Kubernetes).
With those features in mind, here’s how the stack lays out on K8s.
Architecture
Development / Staging
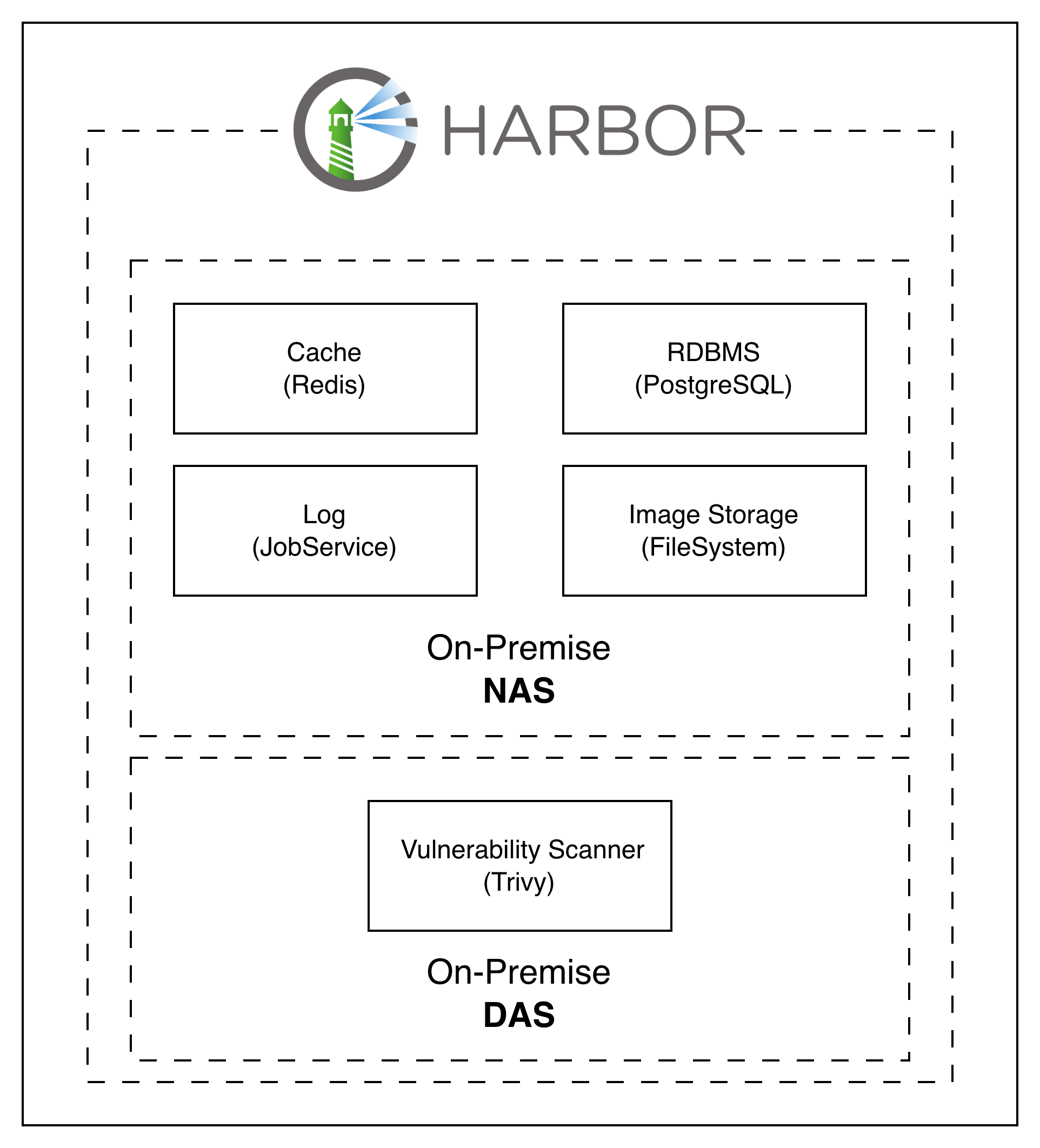 Single-node Harbor on K8s: four core services backed by NAS, Trivy on DAS
Single-node Harbor on K8s: four core services backed by NAS, Trivy on DAS
For Harbor to run, four services need to be available:
- Cache
- Log
- RDBMS
- Storage (for image containers)
The Vulnerability Scanner is strongly recommended (default integration is Trivy).
Apart from the storage choice, every service runs with default options. NAS over DAS: NAS adds a small communication-latency hit, but it gives a single source of truth — Harbor stores layers in a content-addressed structure (each unique layer once), and NAS makes that store shared across workers instead of fragmenting copies onto each worker’s disk. Replication targets one volume instead of many, and there’s no risk of a worker pinning images to its local disk and losing them when the pod is rescheduled. Per-worker DAS would speed up cold pulls but trades that for fragmented storage and coherency headaches.
Production
Harbor has not been used for production at my company — this section is the result of research, an implementation, and verification tests, not battle-tested deployment.
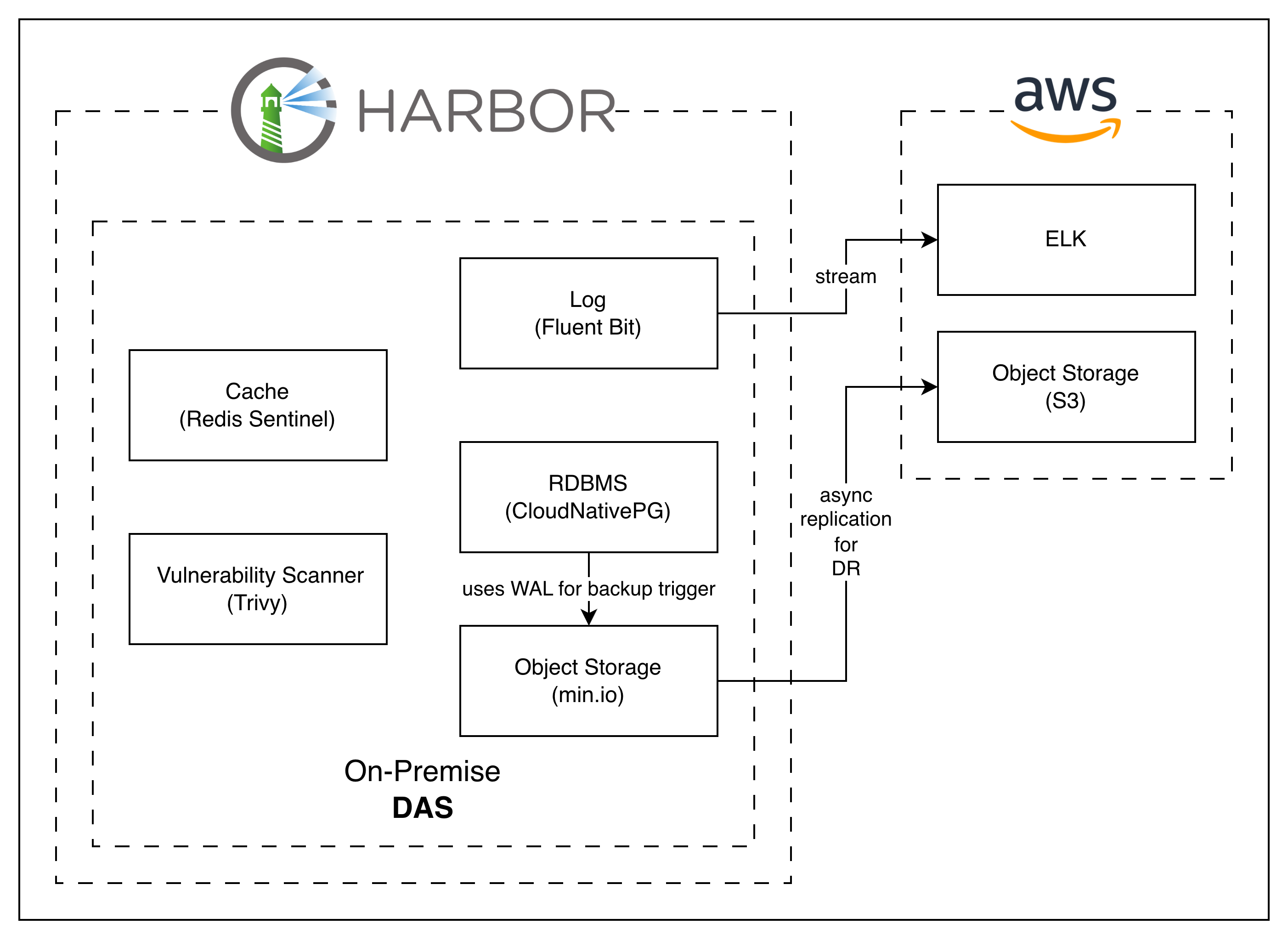 Production Harbor: each component HA’d via its own native primitive, with WAL→S3 DR to AWS
Production Harbor: each component HA’d via its own native primitive, with WAL→S3 DR to AWS
The biggest shift from dev: storage moves to per-worker DAS, with each component layering its own fault-tolerance primitive on top so the distributed setup actually holds.
- Cache: Redis Sentinel — quorum-based monitor with automatic failover between Redis instances. Sentinel (not Redis Cluster) is the right fit here: Harbor’s cache workload is small and single-keyspace, so Cluster’s sharding adds complexity without benefit.
- Log: Fluent Bit — a daemon per worker that streams logs to AWS ELK. The heavy lifting (indexing, retention, search) lives off-cluster; on-prem only runs the lightweight forwarder.
- RDBMS: CloudNativePG — Kubernetes operator that manages PostgreSQL with replica + leader-promotion failover. Operator-managed PG matches K8s primitives, and WAL is exposed for the DR pipeline described below.
- Storage: MinIO — S3-compatible object store running in distributed mode with erasure coding. Durability without bringing in an actual object-store service.
For DR: PostgreSQL WAL ships to MinIO as the first hop, then MinIO async-replicates to AWS S3. RPO is bounded by replication lag (minutes, not seconds). The Harbor application itself is backed up via Velero (officially recommended by Harbor) — K8s-native cluster-state snapshots, restored to a recovery cluster if the primary site is lost.
Two operational settings that aren’t optional in production: per-project quotas to cap storage growth, and garbage collection scheduled for untagged manifests. Without GC, every overwritten tag leaves dangling layers behind and storage grows monotonically.
In Action
Here’s Harbor sitting in a full CI/CD pipeline — GitHub Actions builds an image on an ARC runner, pushes it to Harbor, and ArgoCD picks the new tag up from there. The CI and CD halves are covered in their own posts; this clip is the end-to-end view with Harbor as the registry in the middle.
Live demo: the full CI/CD pipeline with Harbor as the registry