Deployment Strategies: Blue Green and Canary
Comparing Blue Green and Canary deployment strategies on Kubernetes with Argo Rollouts — flow, traffic shaping, and when each fits
Summary
The default Kubernetes Deployment uses a rolling update — straightforward, but it offers no smoke-test gate before the new version is exposed to real traffic. Two strategies fix that: Blue Green swaps all traffic to the new version atomically after testing; Canary ramps traffic to the new version gradually while watching metrics. Both are first-class concepts in Argo Rollouts, which sits on top of Kubernetes Deployments and adds the orchestration these patterns need.
This post walks through both flows on Argo Rollouts, then notes where each fits.
Prerequisites — CI/CD Flow
| Layer | Tool |
|---|---|
| Deploy target | Kubernetes (K8s) |
| CI | GitHub Actions |
| CD | ArgoCD |
| Deployment strategy | Argo Rollouts |
GitHub Actions builds and pushes the image; ArgoCD syncs the rendered manifests into the cluster; Argo Rollouts owns the deployment behavior itself — swapping the stock Deployment resource for a Rollout resource that understands the strategies below.
K8s Default Deployment
By default, K8s uses a rolling update — pods are replaced one batch at a time until the new version is fully serving traffic.
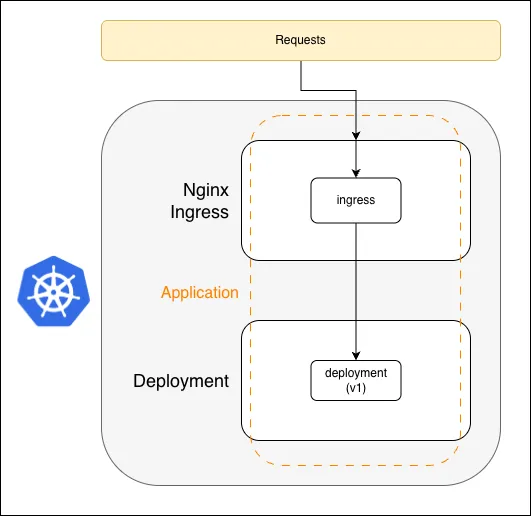 Standard K8s: one ingress, one Deployment, rolling update on changes
Standard K8s: one ingress, one Deployment, rolling update on changes
The problem isn’t the rolling update itself — it’s that real traffic hits the new version before anyone has actually tested it end-to-end in this cluster, against the dependencies it’s actually wired to.
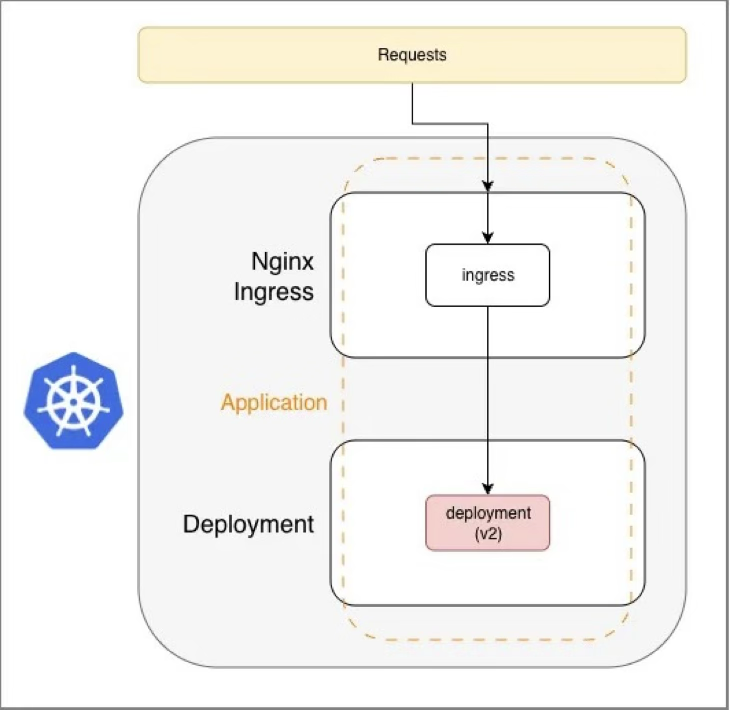 When v2 is misconfigured against external dependencies (DBs, APIs, downstream services), requests still get routed to it and fail
When v2 is misconfigured against external dependencies (DBs, APIs, downstream services), requests still get routed to it and fail
A rollback recovers, but after users have already seen errors. The strategies below add a gate: deploy the new version, smoke-test it in-cluster against real dependencies, then decide whether to expose it to traffic.
Argo Rollouts: Blue Green Deployment
Blue Green keeps both versions running side-by-side. “Blue” and “Green” are just labels — at any moment one is stable (serving real traffic) and the other is preview (deployed but only reachable via a special preview header). The roles flip each release.
1. Standby
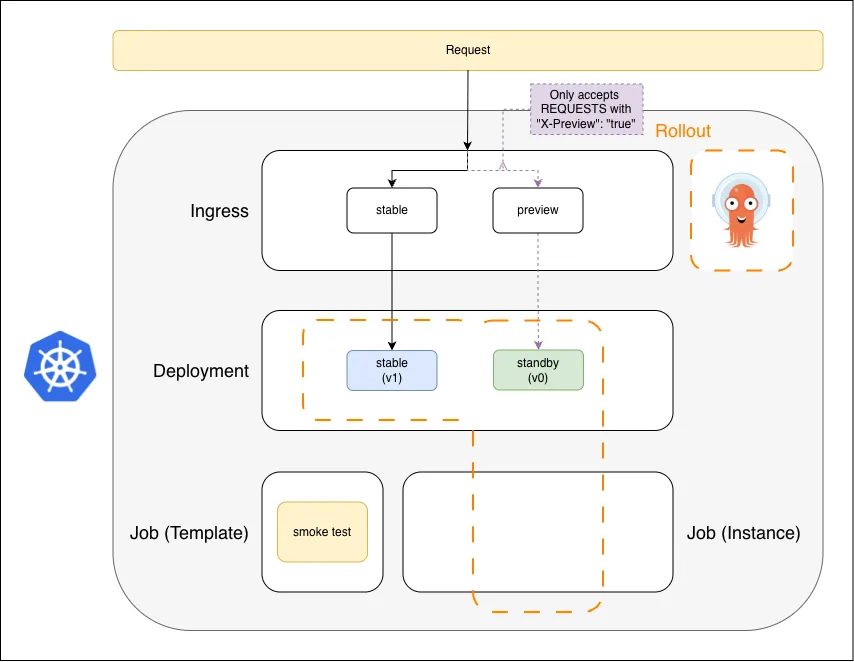 Standby: stable serves real traffic; preview ingress is wired but the target Deployment doesn’t exist yet
Standby: stable serves real traffic; preview ingress is wired but the target Deployment doesn’t exist yet
Two Ingress entries exist already — stable for real traffic, preview accepting only requests with X-Preview: true. The smoke test exists as a Job template (not running). Only the stable Deployment (v1) is up.
2. New Version Deployment
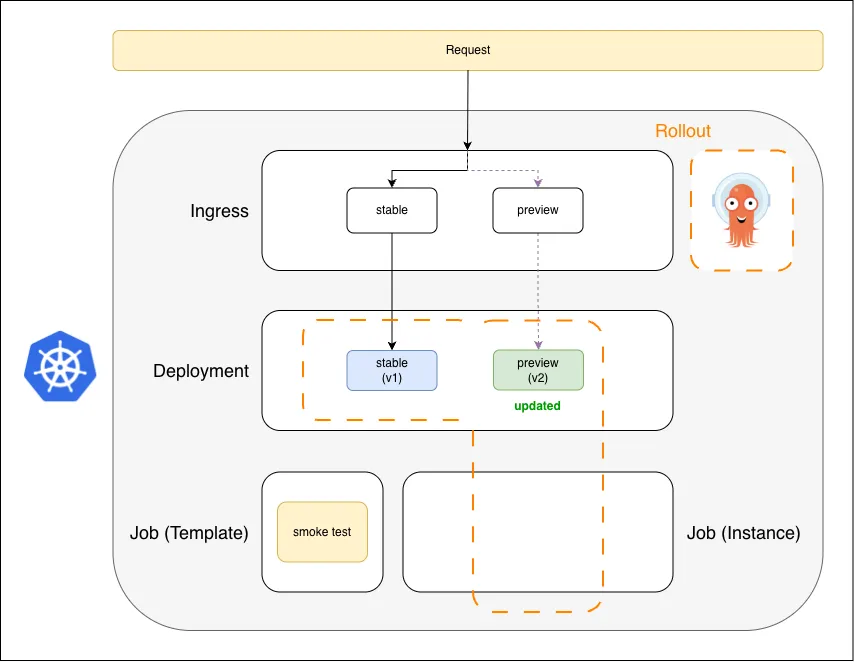 Argo Rollouts spins up the preview Deployment (v2); real traffic continues to v1
Argo Rollouts spins up the preview Deployment (v2); real traffic continues to v1
The Rollout controller spins up v2 as the preview Deployment. It’s reachable only via the preview ingress (the X-Preview header). Real users are still served entirely by v1.
3. Smoke Test Trigger
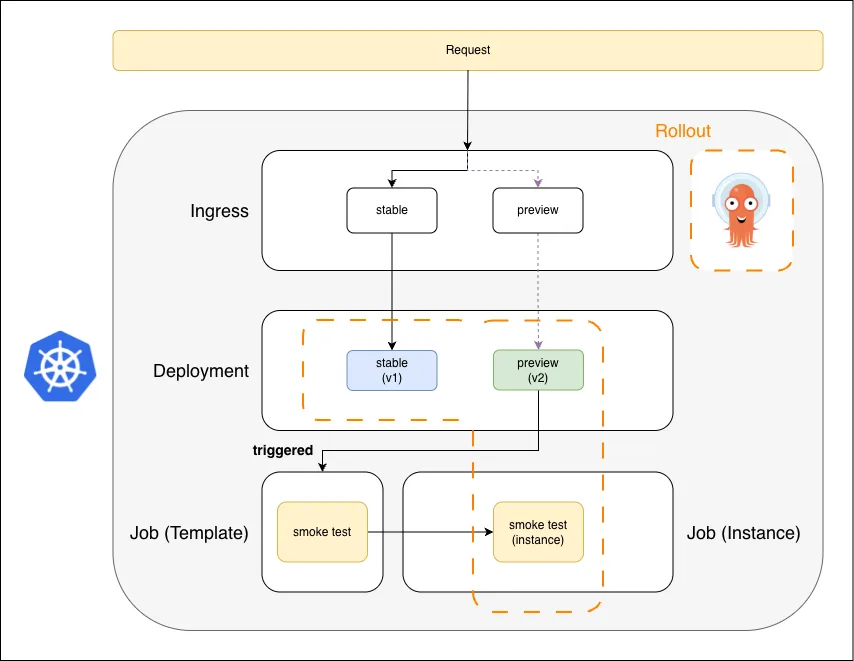 Smoke test Job instance is created from the template
Smoke test Job instance is created from the template
Once v2 is up, the Rollout triggers the smoke test Job. The template becomes a running Job instance.
4. Smoke Test
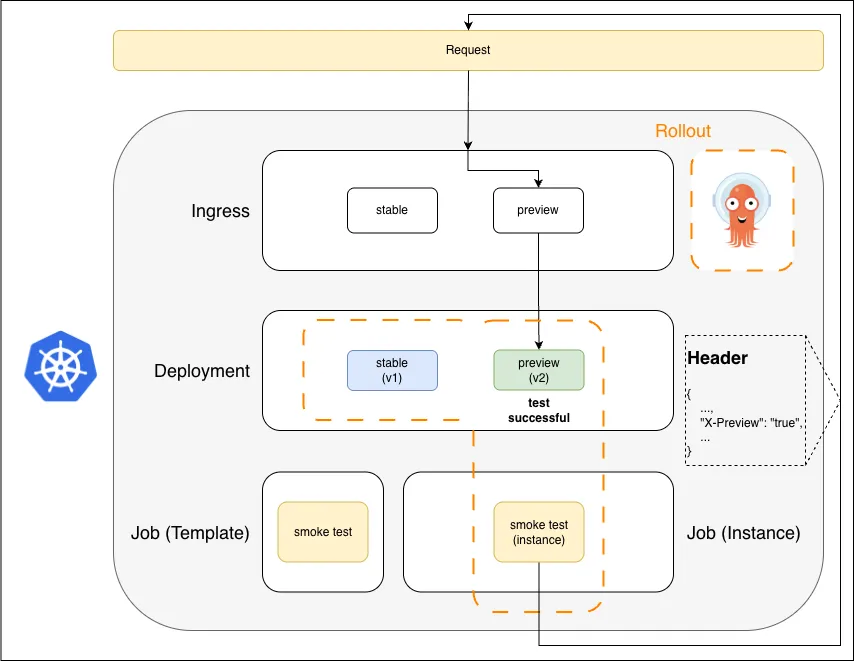 Smoke test sends X-Preview-tagged requests; they hit v2 only. Test passes.
Smoke test sends X-Preview-tagged requests; they hit v2 only. Test passes.
The Job sends requests carrying X-Preview: true. Those land on the preview ingress, which routes them to v2. Real traffic is untouched. If the test fails, the Rollout aborts and v2 is torn down — users never saw it.
5. Cutover and Re-Organize
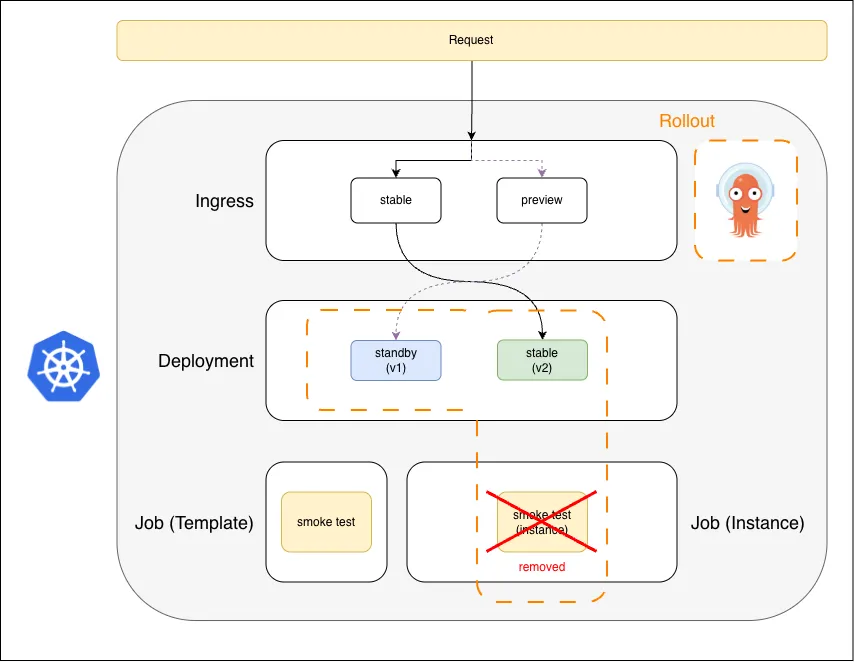 Labels flip atomically: v2 is the new stable, v1 is held in standby for rollback; smoke test instance is cleaned up
Labels flip atomically: v2 is the new stable, v1 is held in standby for rollback; smoke test instance is cleaned up
The stable label flips from v1 to v2 in a single atomic switch. All real traffic now hits v2 instantly. v1 is held in standby for a configurable window so that, if a problem surfaces post-cutover, rolling back is a label flip rather than a redeploy. The smoke test instance is cleaned up.
Argo Rollouts: Canary Deployment
Canary takes its name from canaries in coal mines — sensitive birds that gave miners early warning of toxic gas. Same idea here: route a small slice of real traffic to the new version, watch its metrics, and only ramp up if it stays healthy.
1. Standby
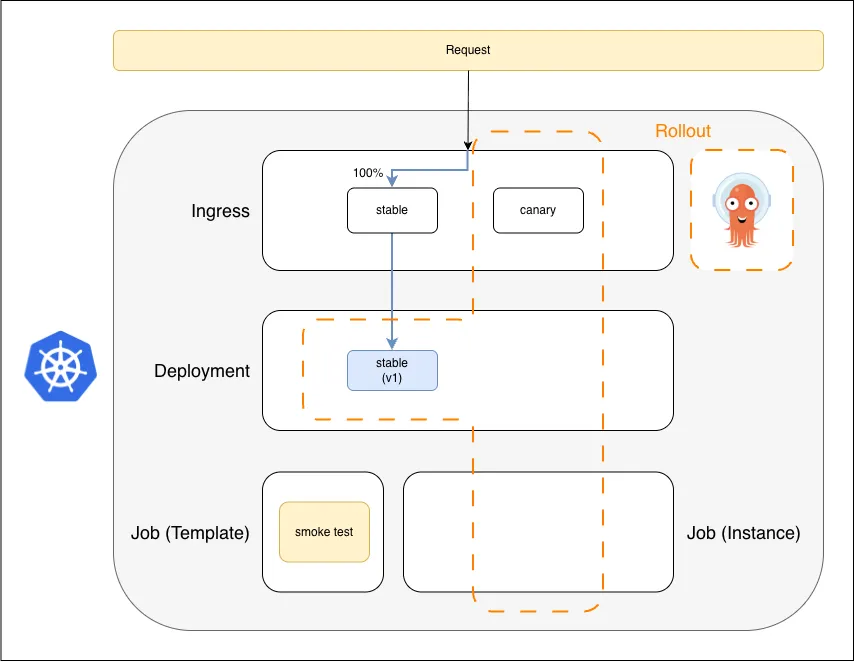 Standby: stable receives 100% traffic; canary ingress is wired but has no target
Standby: stable receives 100% traffic; canary ingress is wired but has no target
Same shape as Blue Green at rest — but the second ingress is canary, not preview.
2. New Version Deployment
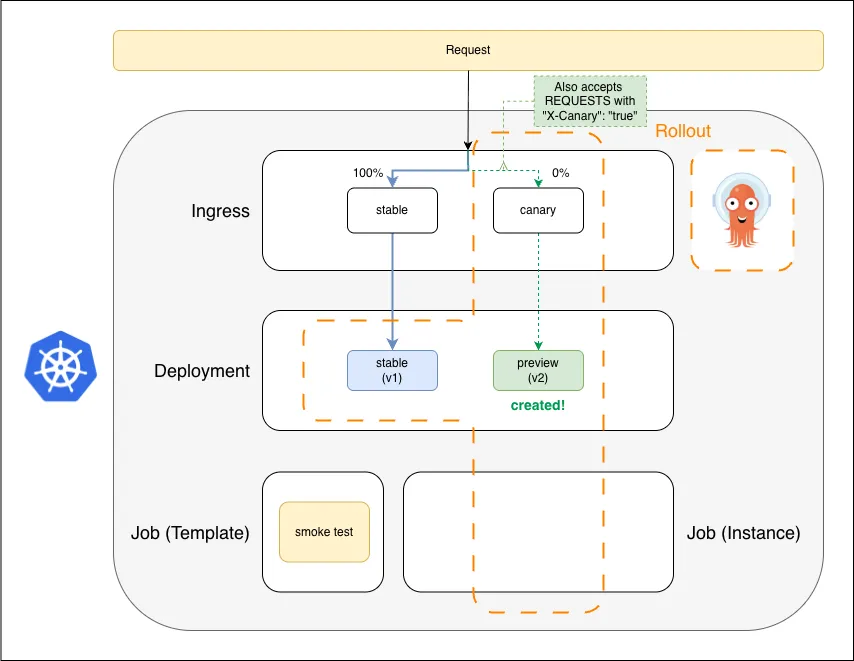 Preview (v2) is up; canary ingress accepts the X-Canary header but is still at 0% real traffic
Preview (v2) is up; canary ingress accepts the X-Canary header but is still at 0% real traffic
v2 comes up as preview. The canary ingress accepts X-Canary: true for testing, but none of the real traffic is routed there yet.
3. Smoke Test Trigger
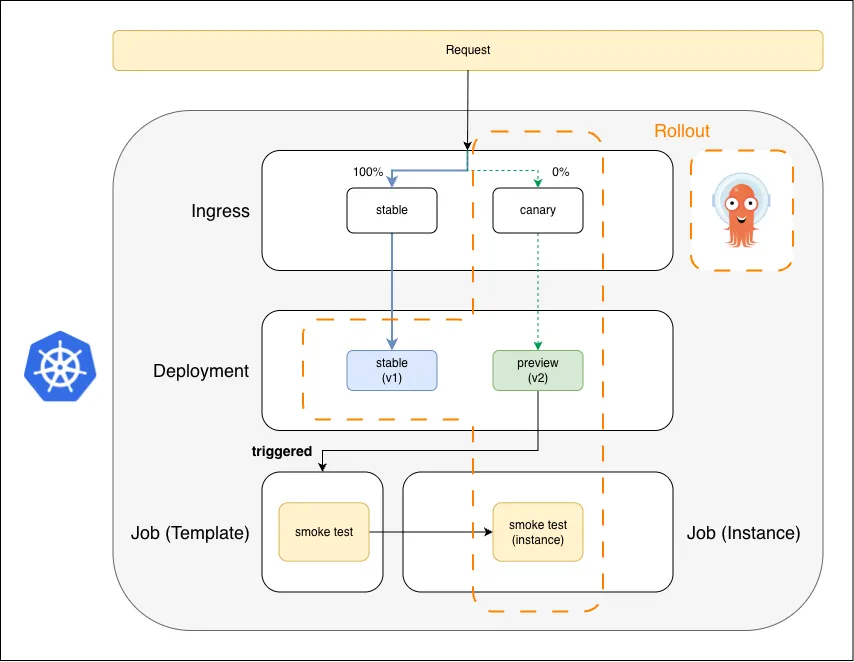 Smoke test instance is created from the template — same mechanism as Blue Green
Smoke test instance is created from the template — same mechanism as Blue Green
Same mechanism as Blue Green: the Rollout triggers the smoke test Job.
4. Smoke Test
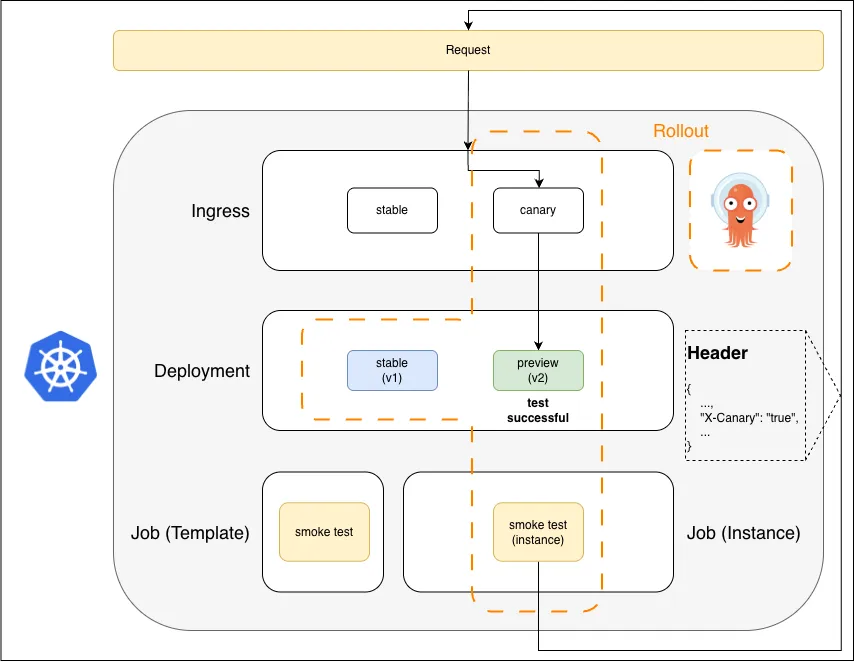 Smoke test uses X-Canary against v2. Test passes. Real traffic still 100% on v1.
Smoke test uses X-Canary against v2. Test passes. Real traffic still 100% on v1.
The smoke test sends X-Canary: true requests; they hit v2. Real traffic is still 100% on v1.
5. Incremental Traffic Distribution
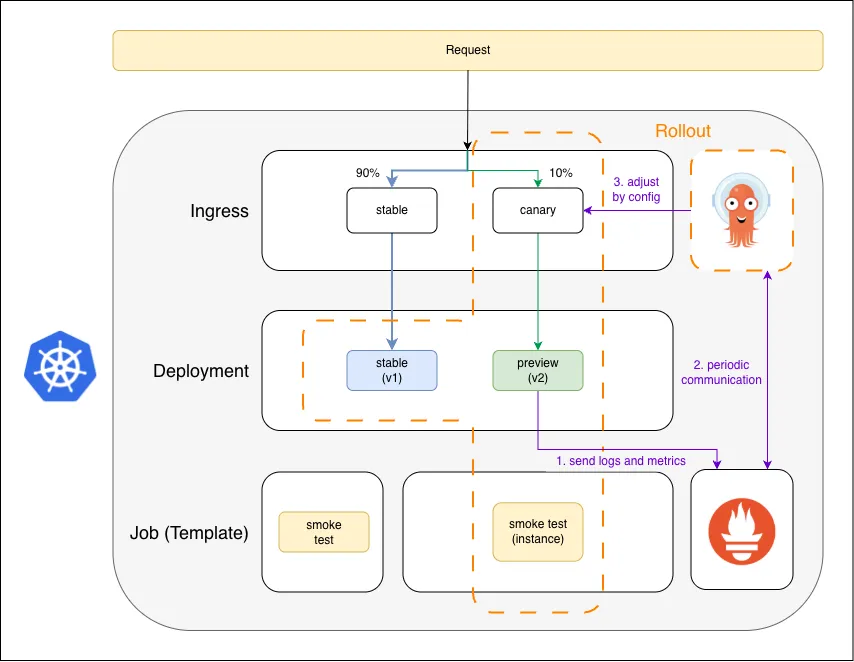 Traffic split: 90% stable, 10% canary. Prometheus collects v2 metrics; Argo Rollouts steps the split up automatically if metrics stay healthy.
Traffic split: 90% stable, 10% canary. Prometheus collects v2 metrics; Argo Rollouts steps the split up automatically if metrics stay healthy.
This is the part Canary actually does differently. The Rollout shifts a configurable slice of real traffic to v2 — start at 10%, ramp through 25%, 50%, 75%, 100%. Between steps, Argo Rollouts queries Prometheus for the canary’s error rate and latency. If they stay within bounds, the next step fires automatically. If they degrade, the Rollout aborts and traffic snaps back to v1.
6. Cutover and Re-Organize
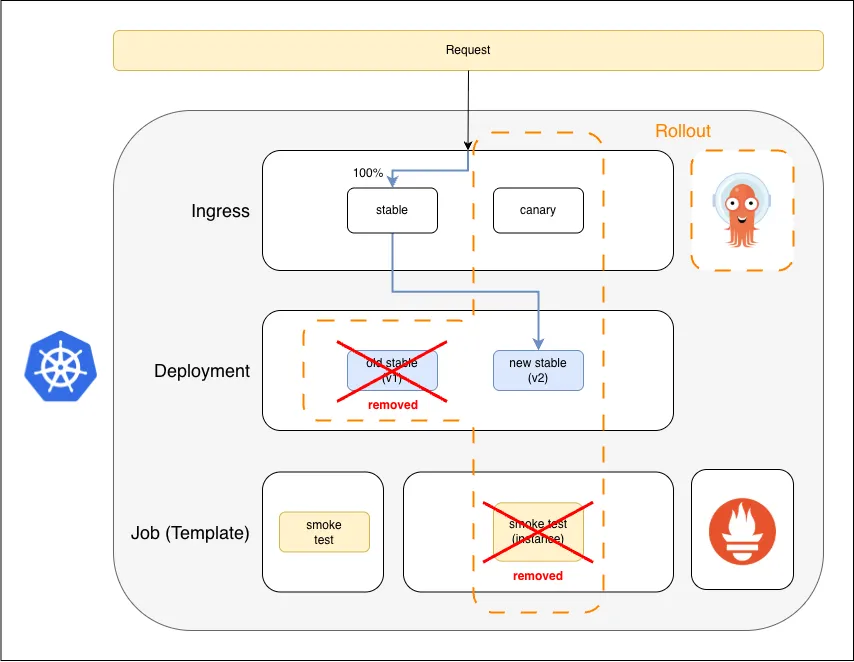 v2 is promoted to stable, v1 is removed, smoke test instance is cleaned up
v2 is promoted to stable, v1 is removed, smoke test instance is cleaned up
Once the ramp completes successfully, the Rollout removes v1 entirely and v2 becomes the new stable. The smoke test instance is cleaned up.
Canary needs a metrics source. Argo Rollouts ships with AnalysisTemplates that can query Prometheus, Datadog, New Relic, CloudWatch, or even a custom HTTP endpoint — the right answer depends on what your observability stack already exposes.
Picking the Right Strategy
| Blue Green | Canary | |
|---|---|---|
| Cutover | Atomic, all-at-once | Gradual, metric-driven |
| Real users see the new version | After cutover | During the ramp |
| Resource footprint while testing | 2× (both versions full-size) | 2× during overlap, canary can start small |
| Needs a metrics source (e.g. Prometheus) | No | Yes |
| Rollback after cutover | Label flip back to v1 | Snap traffic back to stable |
| Best fit | Server-side and B2B | Client-side and B2C |
Blue Green is the natural fit for server-side and B2B workloads. Running two versions of a server side-by-side opens up concurrency side-effects — stateful caches, DB schema assumptions, in-flight job ownership — that make a partial traffic split risky. A B2B contract usually also means a small, trusted user base, so an atomic cutover is acceptable, and if something breaks, the rollback flip is just as atomic.
Canary is the natural fit for client-side and B2C workloads. Client instances run independently in each user’s local environment, so a 10% rollout doesn’t create cross-instance contention. And the much larger user base — heterogeneous devices, networks, behaviors — means real-user telemetry is precisely the thing you want before going all-in.
Both strategies still require a smoke test gate before any real traffic hits the new version. The choice between Blue Green and Canary is about what happens after that gate passes, not whether to gate at all.