Deduplication with Rabin Fingerprinting and Variable-Size Chunking
A simple variable-size chunking deduplication system with Rabin fingerprinting and SHA-256 indexing
Introduction
A well-known cloud storage product is Dropbox. Before 2016, Dropbox ran on top of AWS for online storage. Comparing 2014 pricing, AWS charged ~$30/month for 1TB while Dropbox charged $9.99/month for the same 1TB — at face value, Dropbox was losing money on every customer. How did they actually make money?
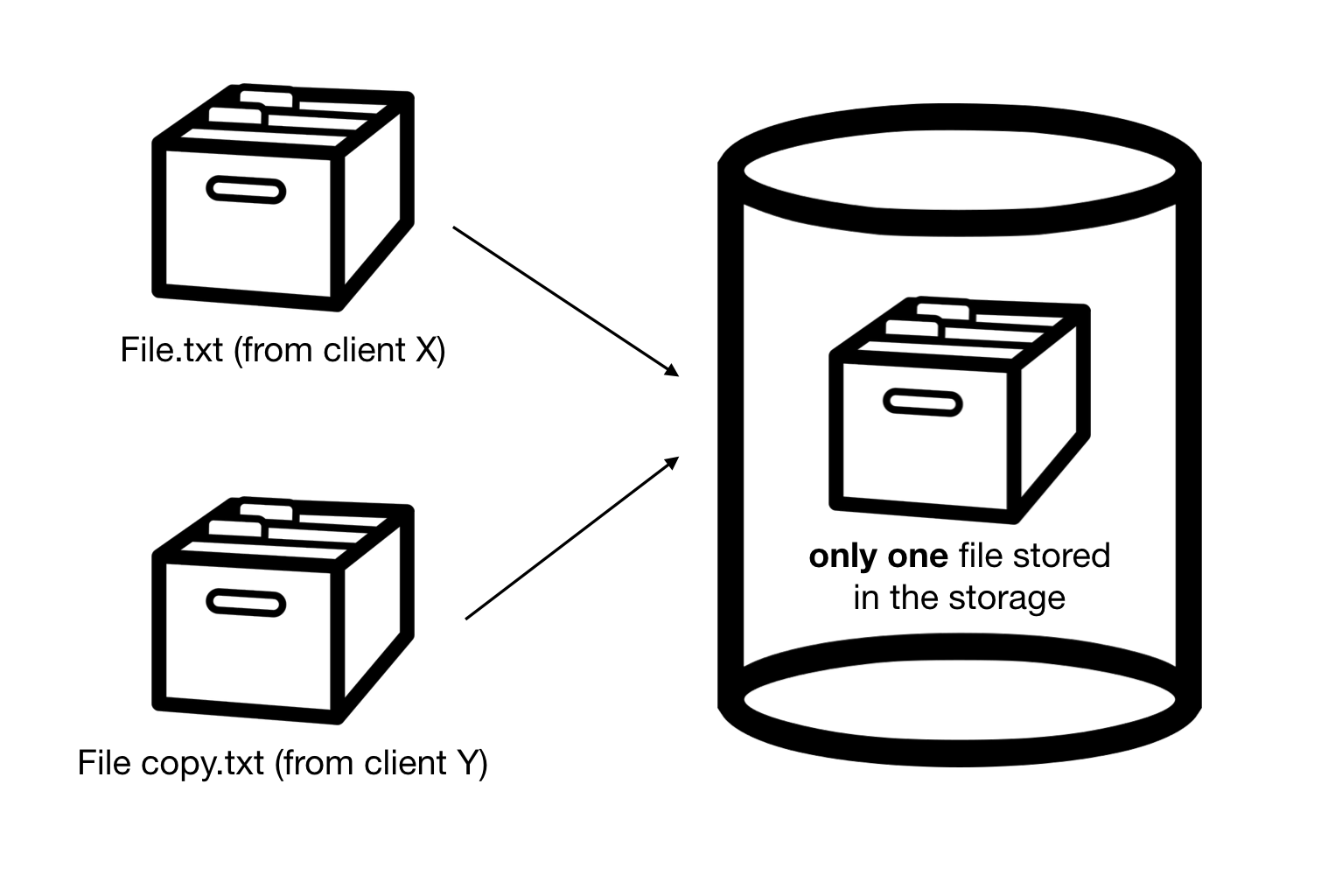
Deduplication is a storage technique that eliminates redundant data — instead of storing multiple copies of the same content, only one copy is kept.
Deduplication can be broken down into three sub-processes:
- Chunking — divide a data stream into chunks
- Fingerprinting — compute a hash for each chunk so it can be identified
- Indexing — look up the fingerprint; if new, upload the chunk and record it; if seen before, store only a reference
Implementation
Chunking
Chunking is conceptually simple, but gets more involved once optimizations are layered on top.
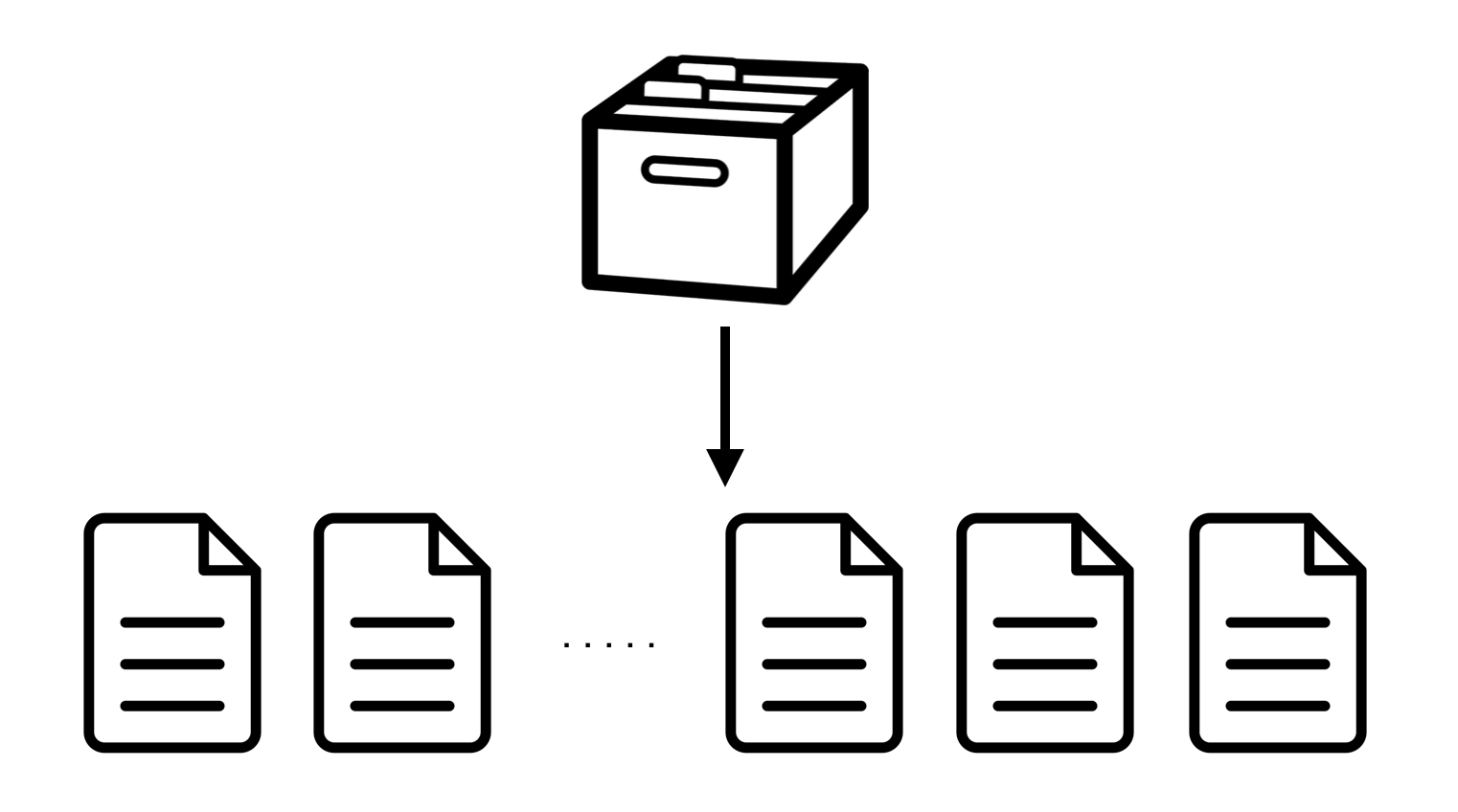
Fixed-size chunking (static chunk size) deduplicates better than whole-file deduplication, but variable-size chunking (content-defined boundaries) is the most effective — at the cost of extra computation per chunk. This program uses variable-size chunking.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
public class Chunk implements Serializable {
public int refCounter;
public MainStorage.StorageType type;
public byte[] data;
public Chunk(byte[] data) {
this.data = data;
this.refCounter = 1;
}
public Chunk(MainStorage.StorageType type, int refCounter) {
this.type = type;
this.refCounter = refCounter;
}
public void setData(byte[] data) {
this.data = data;
}
public void increment() {
this.refCounter++;
}
public void decrement() {
this.refCounter--;
}
public boolean shouldDelete() {
return this.refCounter <= 0;
}
}
Fingerprinting
A cryptographic hash (e.g. SHA-1, MD5, SHA-256) is computed for each chunk and compared against existing fingerprints. There’s a theoretical collision risk (two different chunks hashing to the same value), but the probability is negligible for cryptographic hashes.
For chunk-boundary detection, a rolling hash like the Rabin–Karp algorithm (Rabin fingerprinting) is commonly used. In short, it’s a polynomial hash that can be updated in O(1) as the window slides byte-by-byte — making it cheap to evaluate at every position to decide whether a byte boundary should become a chunk cut.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
// initializing values for computation
b = in.read();
int rfp = 0;
int data = (int) (b & 0xFF);
if(b != -1) {
byteStore.put((byte) data);
offset++;
size++;
} else if(offsets.get(offsets.size() - 1) != offset) {
offsets.add(offset);
chunkFound = true;
}
// Checking if the chunk is unique
if(chunkFound == false) {
if(size >= request.m) {
if(size == request.m) {
for(int i = 1; i <= request.m; i++) {
int t = byteStore.get(i - 1);
int e = request.m - i;
int mod = (int) modExpOpt(request.d, e, request.q);
rfp += (t * mod) % request.q;
}
rfp = rfp % request.q;
} else if(size > request.m) {
int lastByte = byteStore.get(size - request.m);
int q = request.q;
int d = (request.d % request.q);
int psMinus1 = (lastRfp % request.q);
int d_mMinus1 = (preMod % request.q);
int ts = (lastByte % request.q);
int tsPlusM = (data % request.q);
int tempPart1 = ((d_mMinus1 % q) * (ts % q)) % q;
int tempPart2 = ((psMinus1 % q) - tempPart1) % q;
rfp = ((((d % q) * (tempPart2)) % q) + (tsPlusM % q)) % q;
if(rfp < 0) {
rfp += request.q;
}
}
if(rfp == 1) {
offsets.add(offset);
chunkFound = true;
}
}
lastRfp = rfp;
}
// if chunk is unique create index
if(chunkFound == true) {
byte[] chunk = Arrays.copyOfRange(byteStore.array(), 0, size);
MessageDigest md = MessageDigest.getInstance("SHA-256");
md.update(chunk, 0, size);
byte[] checksumInByte = md.digest();
String checksum = new BigInteger(1, checksumInByte).toString(16);
Chunk ch = index.chunks.get(checksum);
if (ch == null) {
ch = new Chunk(1);
storage.put(checksum, new Chunk(chunk));
bytesUploaded += size;
chunksUploaded++;
localChunks.put(checksum, 0);
} else {
if(localChunks.get(checksum) == null){
localChunks.put(checksum, 0);
ch.increment();
}
}
index.chunks.put(checksum, ch);
chunks.add(checksum);
byteStore.clear();
size = 0;
chunkFound = false;
}
Indexing
The index could live in RAM, but it doesn’t scale: 1TB of storage with 4KB chunks and a SHA-256 (32-byte) digest per chunk needs ~8GB of RAM just for the index — and that grows linearly with stored data, so any multi-TB deployment makes RAM-only indexing impractical. This program uses disk instead.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
public class Index implements Serializable {
public TreeMap<String, ArrayList<String>> files;
public TreeMap<String, Chunk> chunks;
public Index() {
this.files = new TreeMap<String, ArrayList<String>>();
this.chunks = new TreeMap<String, Chunk>();
}
public boolean hasFile(String pathName) {
return files.containsKey(pathName);
}
public ArrayList<Entry<String, Chunk>> getChunks(String pathName) {
ArrayList<Map.Entry<String, Chunk>> chunks = new ArrayList<Map.Entry<String, Chunk>>();
for (String hash : files.get(pathName)) {
chunks.add(new MutablePair<String, Chunk>(hash, this.getChunk(hash)));
}
return chunks;
}
public HashMap<String, Chunk> getUniqueChunks(String pathName) {
HashMap<String, Chunk> chunks = new HashMap<String, Chunk>();
for (String hash : files.get(pathName)) {
chunks.put(hash, this.getChunk(hash));
}
return chunks;
}
public ArrayList<String> getChunkHashes(String pathName) {
return files.get(pathName);
}
public boolean hasChunk(String hash) {
return chunks.containsKey(hash);
}
public Chunk getChunk(String hash) {
return chunks.get(hash);
}
}
Results
A plain-text copy of A Tale of Two Cities from gutenberg.org is used as the test corpus.
Commands
1
2
3
$ java Deduplication upload [min size] [avg size] [max size] [base parameter] [filename]
$ java Deduplication download [downloading filename] [downloaded filename]
$ java Deduplication delete [filename]
The first upload is the original file:
1
2
3
4
5
6
7
8
$ java Deduplication upload 128 256 512 1 tale-of-two-cities-1.txt
-------------------- Upload Report --------------------
Chunks: 2343
Unique Chunks: 2343
Total Bytes Deduplicated: 787075
Total Bytes Not Deduplicated: 787075
Duplication Ratio: 0.00%
-------------------- End Upload Report --------------------
All chunks are unique — nothing has been uploaded yet, so there’s nothing to deduplicate against.
For the second upload, a few paragraphs are deleted from the text file so it no longer matches the first byte-for-byte:
1
2
3
4
5
6
7
8
$ java Deduplication upload 128 256 512 1 tale-of-two-cities-2.txt
-------------------- Upload Report --------------------
Chunks: 2345
Unique Chunks: 3
Total Bytes Deduplicated: 1073
Total Bytes Not Deduplicated: 788059
Duplication Ratio: 99.86%
-------------------- End Upload Report --------------------
Since most of the file is unchanged, the vast majority of its chunks are duplicates of the first upload — only 3 new chunks are uploaded.
Downloading the modified file:
1
2
3
4
5
6
$ java Deduplication download tale-of-two-cities-2.txt tale-of-two-cities-2-copy.txt
-------------------- Download Report --------------------
Chunks Downloaded: 2345
Total Bytes Downloaded: 789132
Total Bytes Reconstructed: 788059
-------------------- End Download Report --------------------
Reconstructed bytes are the portion of the file assembled from chunks already in storage (shared with other files); the remaining ~1KB came from this file’s own unique chunks.
Deleting the modified file:
1
2
3
4
5
$ java Deduplication delete tale-of-two-cities-2.txt
-------------------- Delete Report --------------------
Chunks Deleted: 3
Bytes Deleted: 1073
-------------------- End Delete Report --------------------
The remaining chunks are still referenced by the original file, so only the 3 chunks unique to the modified file are actually deleted.
Deleting the original file instead of the modified one:
1
2
3
4
5
$ java Deduplication delete tale-of-two-cities.txt
-------------------- Delete Report --------------------
Chunks Deleted: 1
Bytes Deleted: 128
-------------------- End Delete Report --------------------
Only 1 chunk isn’t shared with the modified file, so only that single chunk is deleted. The report shows 128 bytes (the configured min size for chunks), but the actual unique content is 89 bytes — the rest is zero-padding.