Hadoop In-Mapper Combiner
A Hadoop pattern that trades mapper memory for shorter MapReduce runtime
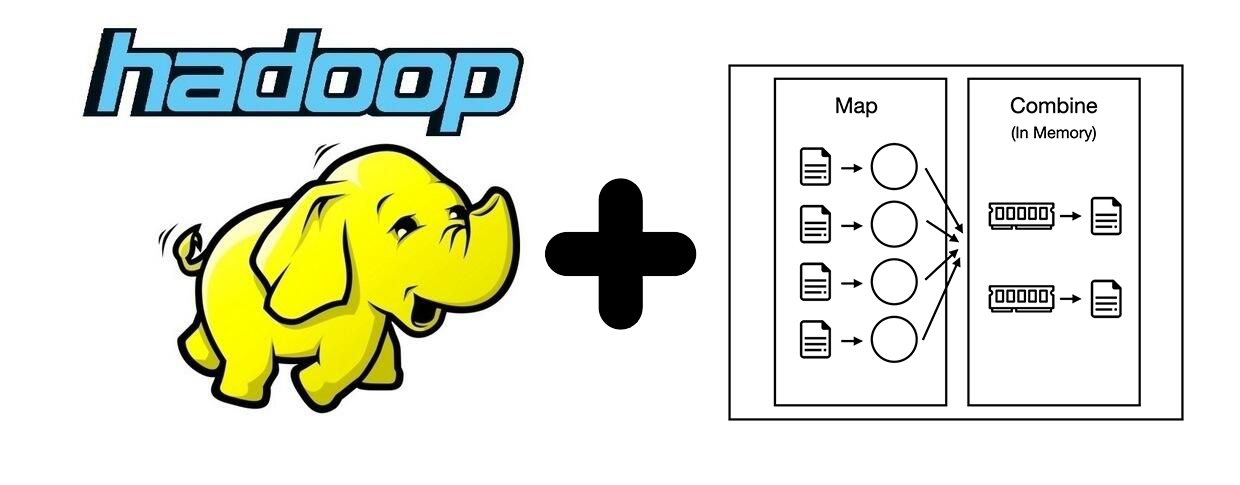
Summary
The in-mapper combiner trades memory for runtime — each mapper aggregates locally before emitting, cutting the number of (key, value) pairs the shuffle phase has to move.
Hadoop’s standard combiner runs on each mapper’s output (after map, before shuffle) and re-aggregates pairs the mapper has already emitted. The in-mapper variant pulls that aggregation into the mapper itself, so the mapper emits far fewer pairs in the first place. The trade-off: per-mapper state has to be held in memory until the mapper finishes, which raises memory overhead per mapper.
In practice you’d usually tweak the broader MapReduce pipeline too, but this example is a simple word-length count, so the surrounding pipeline is left alone.
Traditional Combiner
Sample input — "The brown fox jumps over the lazy dog"
Sample output — (3, 4), (4, 2), (5, 2) → tuples of (word length, count)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
public static class Map extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
String token = itr.nextToken();
int length = token.length();
word.set(length+"");
context.write(word, one);
}
}
}
The emitted key is Text rather than IntWritable — IntWritable would be the more natural choice, but this was adapted from a standard WordCount program where the key was already Text.
From Traditional to In-Mapper Combiner
Pseudocode
1
2
3
4
5
6
7
8
9
10
11
class Map
initialize count ← new AssociativeArray (HashMap here)
method map
for each token in input
if length seen before → count[length] += 1
else → count[length] = 1
method cleanup
for each (length, count) in the AssociativeArray
emit (length, count)
cleanup is required because map() itself never emits in this variant — it only updates the local HashMap. The accumulated counts only reach the reducer when cleanup() flushes them at the end of the split; without it, the mapper produces no output at all.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
public static class Map extends Mapper<Object, Text, Text, IntWritable> {
Map count = new HashMap<Integer, Integer>();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
String token = itr.nextToken();
int length = token.length();
if(count.containsKey(length)) {
int sum = (int) count.get(length) + 1;
count.put(length, sum);
}
else {
count.put(length, 1);
}
}
}
public void cleanup(Context context) throws IOException, InterruptedException {
Iterator<Map.Entry<Integer, Integer>> temp = count.entrySet().iterator();
while(temp.hasNext()) {
Map.Entry<Integer, Integer> entry = temp.next();
String keyVal = entry.getKey()+"";
Integer countVal = entry.getValue();
context.write(new Text(keyVal), new IntWritable(countVal));
}
}
}
A HashMap is used for the local aggregation. Some of the conversions look awkward because the output key stays as Text rather than IntWritable (carried over from the original WordCount adaptation).
Results
Input — 40MB plain-text file
Cluster — fully distributed: 1 namenode, 2 datanodes
Traditional combiner — ~47 seconds end-to-end:
1
2
3
4
5
6
7
8
9
10
11
18/10/21 09:12:31 INFO mapreduce.Job: Running job: job_1538995042638_0062
18/10/21 09:12:44 INFO mapreduce.Job: map 0% reduce 0%
18/10/21 09:13:00 INFO mapreduce.Job: map 22% reduce 0%
18/10/21 09:13:03 INFO mapreduce.Job: map 36% reduce 0%
18/10/21 09:13:09 INFO mapreduce.Job: map 56% reduce 0%
18/10/21 09:13:10 INFO mapreduce.Job: map 73% reduce 0%
18/10/21 09:13:12 INFO mapreduce.Job: map 77% reduce 0%
18/10/21 09:13:15 INFO mapreduce.Job: map 83% reduce 0%
18/10/21 09:13:16 INFO mapreduce.Job: map 100% reduce 0%
18/10/21 09:13:17 INFO mapreduce.Job: map 100% reduce 100%
18/10/21 09:13:18 INFO mapreduce.Job: Job job_1538995042638_0062 completed successfully
In-mapper combiner — ~29 seconds end-to-end:
1
2
3
4
5
6
18/10/21 09:14:31 INFO mapreduce.Job: Running job: job_1538995042638_0063
18/10/21 09:14:41 INFO mapreduce.Job: map 0% reduce 0%
18/10/21 09:14:53 INFO mapreduce.Job: map 50% reduce 0%
18/10/21 09:14:54 INFO mapreduce.Job: map 100% reduce 0%
18/10/21 09:14:59 INFO mapreduce.Job: map 100% reduce 100%
18/10/21 09:15:00 INFO mapreduce.Job: Job job_1538995042638_0063 completed successfully
About 18 seconds faster on the same 40MB input (~38%), at the cost of holding the per-mapper HashMap in memory until each mapper finishes.
The broader trade-off is the classic space-vs-time exchange: pay more memory in one part of the pipeline (the mapper) to save time elsewhere (the shuffle and reduce). A real deployment has hard limits on both, so knowing where to make that trade is part of the job.