컴퓨터처럼 생각하기
컴퓨터처럼 생각하기 (기본 → 심화) 정리글

Summary
사람이 직관적으로 푸는 문제를 컴퓨터가 풀 수 있는 형태로 어떻게 옮기는지, 두 가지 사례로 풀어본다. 면접에서 받은 Pi 근사값 추정 문제로 추상 → 단계적 분해의 과정을, LeetCode의 Unique Subset 문제로 그 사고가 어떻게 정형 알고리즘과 맞물리는지를 살펴본다.
기본: 문제 번역
Estimate the value of Pi (π) by using a random function that uniformly returns a random value.
이 문제를 처음 들었을 때는 “여기있는 수박으로 태양의 부피를 구해라” 같은 말도 안되는 질문이라고 생각했다. 하지만 사실은 정답보다 문제를 어떻게 풀어나가는지, 그 사고 과정을 보려는 질문이다. 다음과 같이 단계적으로 접근하면 풀이를 풀어내기 수월하다.
1. 반복 작업
“이 랜덤 함수를 Pi (π) 근사값이 나올 때까지 반복적으로 실행한다” → 어떻게 보면 정답이긴 하다. 하지만 이렇게 답하면 “Pi 값을 따로 사용하지 말고 순수히 random function만으로 근사값을 구해야 한다”는 추가 제약조건이 따라붙는다.
그래도 “랜덤 함수를 여러번 호출한다”는 것 자체가 이 문제를 풀기 위한 첫번째 걸음이다. 균등하게 나오는 여러 랜덤값을 어떻게 활용할지가 다음 단계다.
2. 차원 개념
컴퓨터는 1차원 기준이지만, 사람은 1~3차원까지 별도의 설명이나 공식 없이도 직관적으로 이해할 수 있다는 점이 중요하다. 원이라는 개념 자체가 1차원에는 존재하지 않고, 2차원 이상에서만 표현이 가능하다.
일단 x, y 축이 있는 그래프를 만들고, random function이 반환하는 값은 0~1 사이라는 제약조건을 부여한다고 가정하자 (0 ≤ random value ≤ 1).
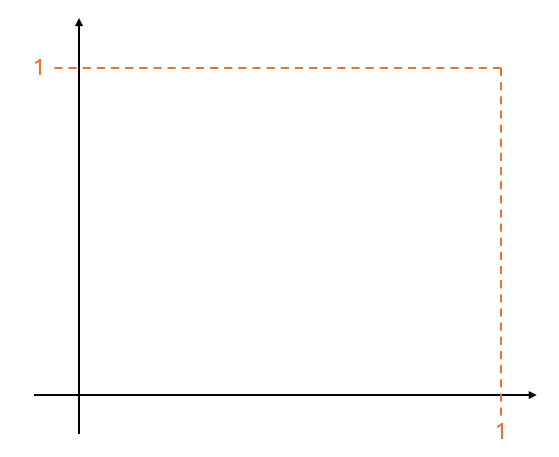
반지름이 1인 원의 중심을 Origin (0,0)에 두면 다음과 같은 그림이 된다.
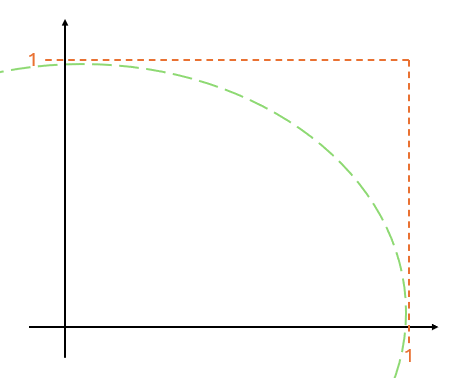
이제 random function의 값을 가져와서 이 그래프에 점을 찍는다고 생각하면 된다. 예를 들어 (0.5, 0.5) 값을 받으면 다음과 같은 그림이 된다.
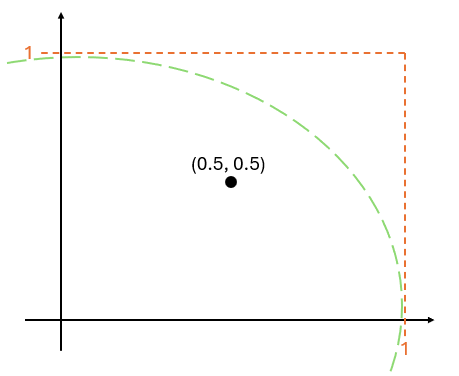
3. 수학 공식
마지막으로 수학 공식을 활용하면 random point가 원 안에 있는지 없는지 판단할 수 있다.
\[\sqrt{x^2 + y^2} = distance\]- 원 내부 → distance ≤ 1
- 원 외부 → distance > 1
다음 단계는 원의 넓이 : 사각형의 넓이 = 원 내부의 점 수 : 전체 점 수 라는 비율을 활용하는 것이다.
\[\pi r^2 : (2r)^2\]r = 1 이라는 제약조건을 넣었으므로 최종 공식은 다음과 같다.
\[\pi = \frac{4 * (distance \le 1)}{(distance > 1)}\]4. 풀이
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
import sys
import random
input = sys.stdin.readline
no_iter = int(input().strip())
in_circle = 0
for _ in range(no_iter):
x = random.uniform(0,1)
y = random.uniform(0,1)
dist = x**2 + y**2
if dist <= 1:
in_circle += 1
est_pi = (4 * in_circle) / no_iter
print(est_pi)
심화: 알고리즘 맵핑
인터넷에서 코딩테스트 관련 vlog을 보다가 알게 된 Find All Unique Subset 문제. 내용은 다음과 같다.
Given an integer array
numsof unique elements, return all possible subsets. The solution set must not contain duplicate subsets. Return the solution in any order.
Example 1:
1
2
Input: nums = [1,2,3]
Output: [[],[1],[2],[1,2],[3],[1,3],[2,3],[1,2,3]]
Example 2:
1
2
Input: nums = [0]
Output: [[],[0]]
Vlog에서는 Combinatorics 공식을 활용해서 총 몇 가지 subset이 가능한지 수학적으로 계산하는 방식을 다뤘는데, 나는 그런 수학적 접근이 익숙하지 않다보니 앞서 얘기한 “기본 1. 반복 작업” 개념을 활용하는 방향으로 생각하게 됐다.
이 문제는 새로운 element를 찾아서 삽입할 때마다 선택지가 생기고, 매 선택마다 파생되는 result를 Tree 자료 구조로 표현해볼 것이다.
1. Naive Approach
Naive하게 생각해서 같은 값을 중복으로 넣지 않는 제약조건만 두고 삽입하는 방식을 택하면, 아래 그림과 같은 Tree가 생긴다. 그림만 봐도 same set, but different order 유형 (예: [1,2], [2,1])이 보이는데, 이런 경우는 그때그때 추가로 삭제해줘야 자료가 폭발적으로 늘어나는 것을 막을 수 있다.
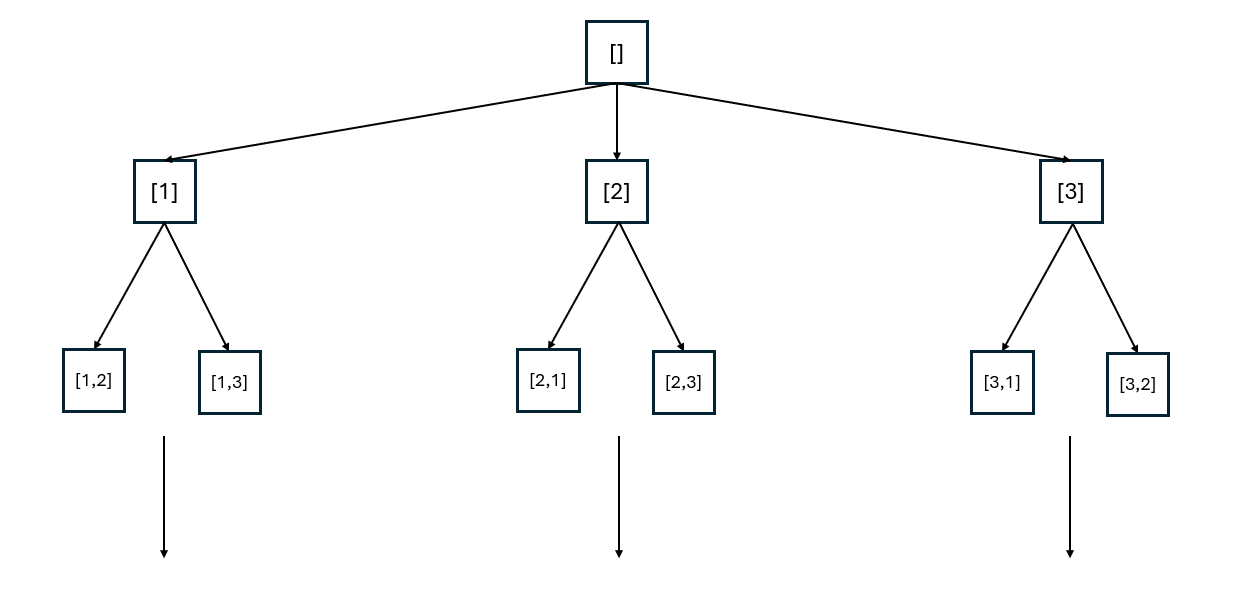 naive approach tree
naive approach tree
2. Naive Approach + Memoization
Naive 방식에 memoization을 추가로 활용한다면, 매번 새로운 선택지가 생성될 때 memoization 여부에 따라 새 값을 만들어 삽입하거나, 이미 계산된 값이면 건너뛰는 선택을 하게 된다.
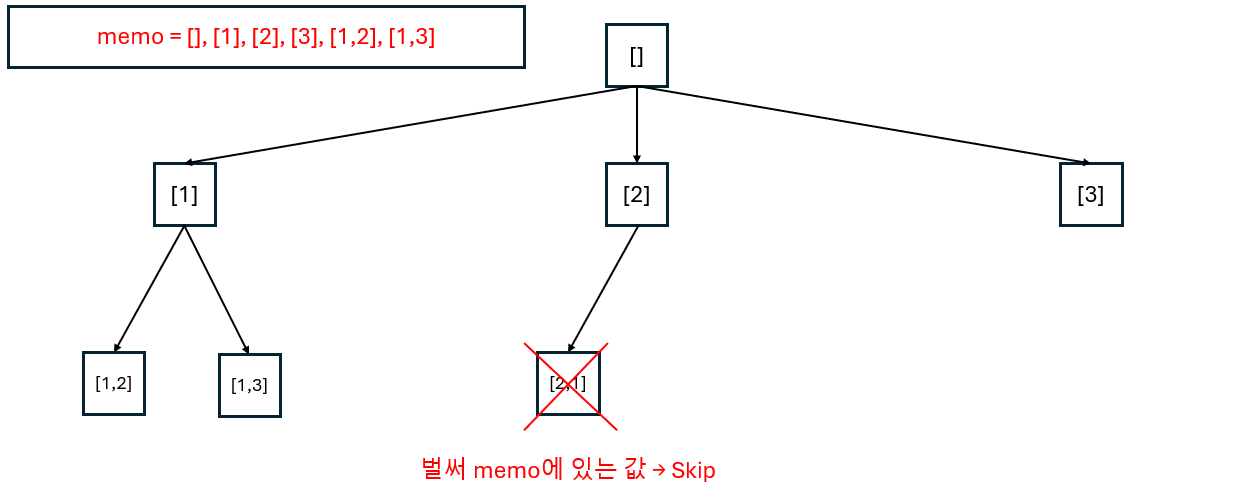 naive + memoization tree
naive + memoization tree
이렇게 풀면 어떻게 보면 매우 비효율적이다 (memo에 같은 값이 있는지 확인할 때 set length * memo length의 시간 복잡도가 생긴다). 하지만 컴퓨터는 반복 작업에 적합하기 때문에, 작은 문제 크기에서는 이렇게 구현해도 충분히 풀 수 있고, 모든 unique subset을 구하는 것도 가능하다.
3. DFS-like Approach
이 문제의 정공법은 정렬된 integer array의 pattern을 활용하는 것이다. DFS를 처음 접하고 연습할 때 많이 보게 되는 유형이다. integer array가 정렬되어 있다는 전제라면, 다음 값은 그냥 현재 값보다 한 단계 큰 값을 가져와서 다음 단계로 넘어가면 된다.
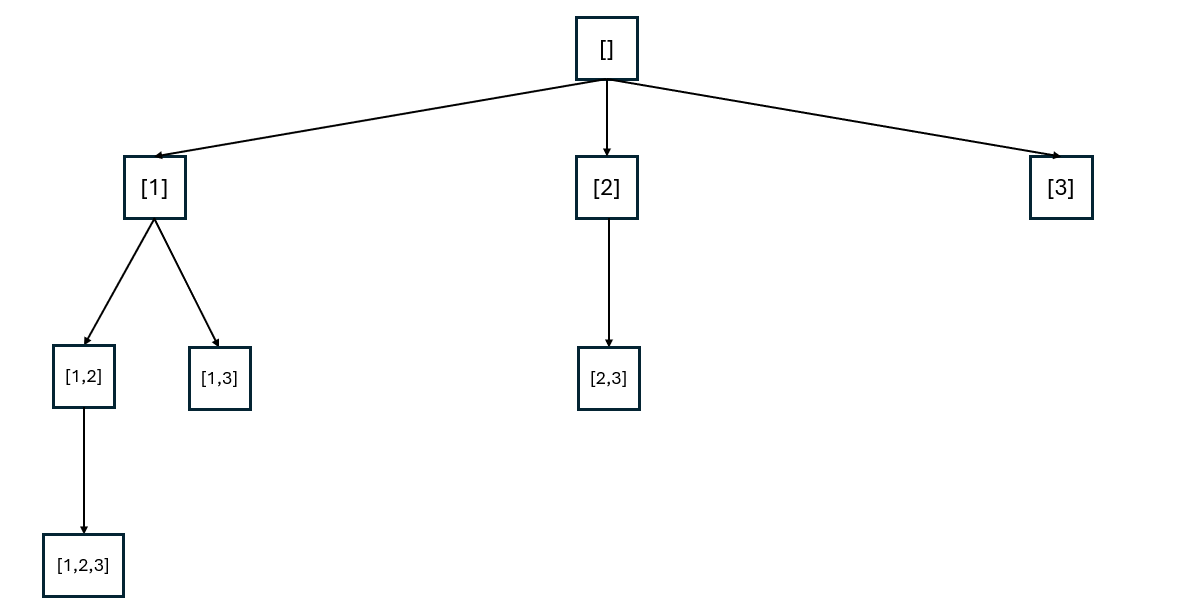 DFS-like approach tree
DFS-like approach tree
pattern을 활용하면 불필요한 subset이 애초에 생성되지 않아서 매우 효율적으로 풀 수 있다. 더 이상 subset을 생성할 수 없다고 판별되면 곧바로 backtracking 하기 때문이다.